Pyhtonを始めたいVBAユーザーの為のPython入門 2
VBAユーザーの為のPython入門
VBAユーザーの為のPYTHON 02回
Excel のブックを読み込んで操作する
この記事で学べる内容
- PythonからExcelブックを読み込んで操作する一連の流れをColab上で体験できる
- Colab(Colaboratory)の「セッション」とは何か、なぜ途中で切れるのか、切れたらファイルが消える理由を理解する
- ColabのセッションストレージにExcelファイルをアップロードして使う手順(/content/ フォルダの扱い)がわかる
- アップロードしたファイルをPythonコード内で指定する書き方(filename = "/content/○○.xlsx")を学ぶ
- openpyxlをインポートして、既存のExcelブックを読み込み、シートを指定して開く基本コードを学べる
- ws.iter_rows(...) を使ってシート内のデータを1行ずつ読み出す方法と、min_row・max_row・max_col・values_onlyなどの引数の意味を理解する
- print()で読み取った行データをそのまま表示して、正しくExcelが読み込めているか確認する実践的な手順を学ぶ
- Excelの最終行を自動で取得する ws.max_row の使い方と、VBAでの最終行取得との違いを確認する
- 6列目の値が160未満の行だけを抽出して、別のExcelブック(補習者.xlsx)に追加する条件つき書き出しの処理を学ぶ
- テンプレートブックを開き、既存の最終行を調べてからデータを追記する「追記型」の書き方を身につける
- 処理結果を別名で保存して、セッションストレージからダウンロードして確認するまでの実務的な流れを理解する
- 次回の「条件に合ったデータを探す」コードにスムーズにつなげるための前提知識(フォルダ・パス・openpyxlの基本)を整理できる
今回はExcelのブックを使って操作してみましょう。
このような操作が「Python(パイソン)」を使うと簡単にできますという例としての紹介です。
すぐに同じことができなくても、気にしなくて大丈夫です。
(Colaboratory で使用したコードは、記事の一番下にあります。)
Colab(正式名称「Colaboratory」)のセッションについて
【セッション】とは
colabには、無料版とpro版の2種類があります。
セッションとはcolabが提供するPythonの実行環境に接続できている状態のことです。
無料のcolabでは12時間、proだと最大24時間GPUを利用できますが、最大時間に到達する前に切れることも多々あります。
どういう状態だと切れるのでしょうか?それは、マウスのクリックやキーを押すといった操作(イベント)が
発生しないと「使っていない」と判断されセッションが切れてしまうのです。
それまでの内容は、当然無くなってしまいます。ですからファイルは作業の度に保存しましょう。
記事の内容は、実際に操作している画像を紹介している動画で見ることができます。
いつでもPythonが使えるように基礎を学ぶ
1. 今回は、以下の2つのエクセル ブックをcolaboratoryで操作します。
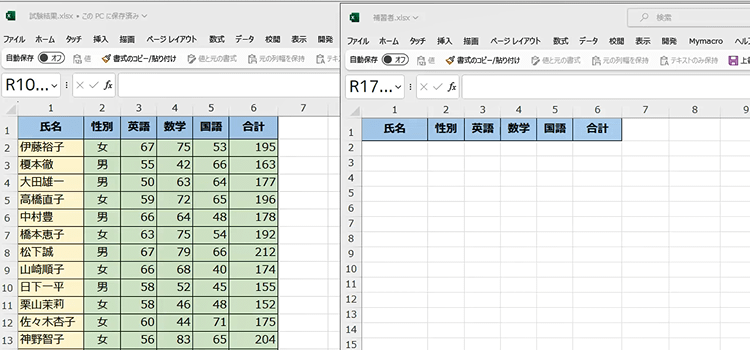
2. そのために Colaboratoryのセッション フォルダーにブックをアップロードします。
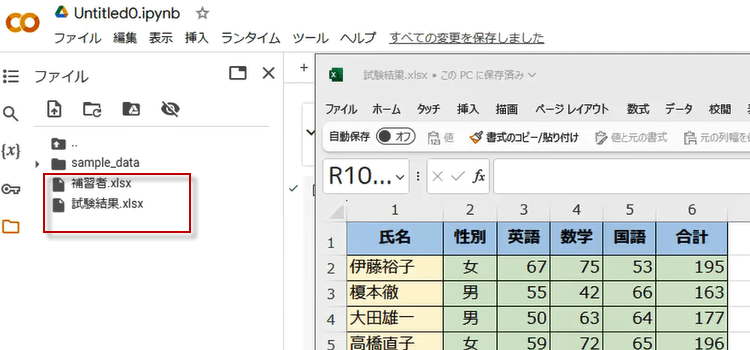
3. もしセッションフォルダが見えない場合は、表示されていないだけです。フォルダのアイコンをクリックしてください。
4.セッションで利用中のフォルダが表示されます。
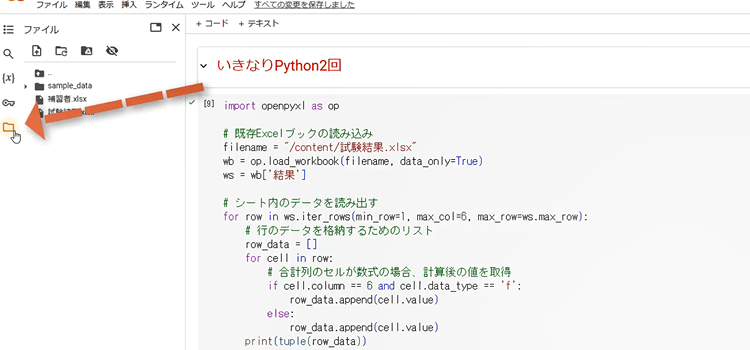
ファイルをセッションストレージにアップロードする方法
5. ブックやファイルをセッションで利用中のフォルダにアップロードするには、アップロードボタンをクリックします。
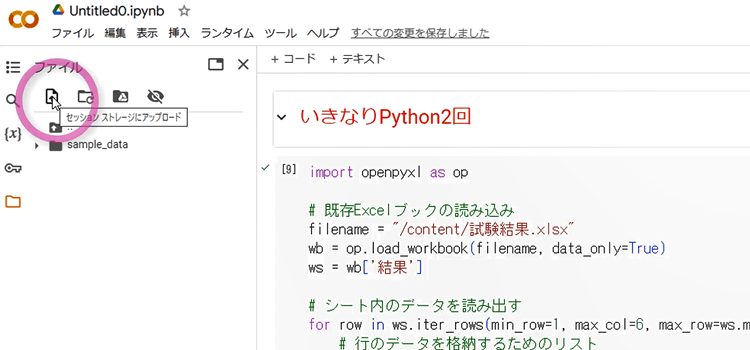
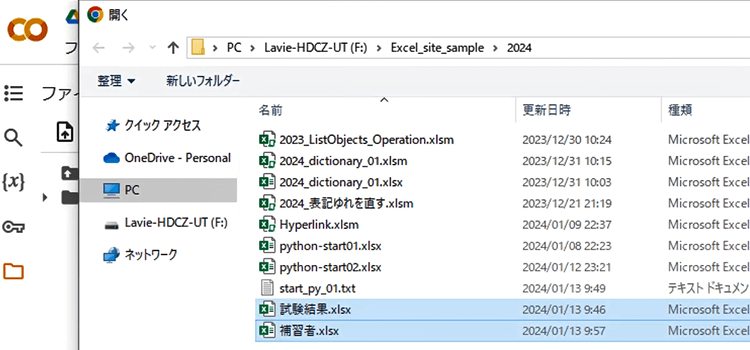
6.次にPC内のフォルダを選択する画面が現れますから、アップロードしたいブックやファイルを選択してください。
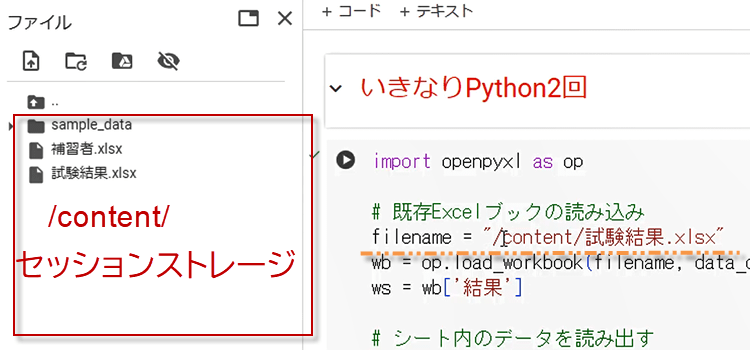
セッションストレージのアドレスをColaboratoryでどう書くのか。
7. セッションストレージのアドレスは/contents/で表すことができます。
つまり、Google Colab で作業している場合、
ファイルがアップロードされるデフォルトのディレクトリは /content/ です。
8. アップロードしたファイルを指定する時は、以下のように書きます。
/contents/を省略することもできます。
filename = "試験結果.xlsx"

Pythonプログラムの実行
9. コードを実行します。まるの中に三角のアイコンをクリックするか、Ctrl+Enterで実行します。

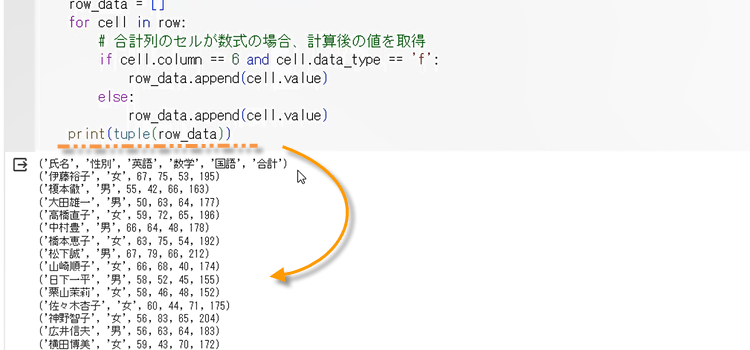
10. データを取得し、それを表示しました。
Pythonコードの意味
11.始めに import openpyxl as op を実行し、openpyxlをインポートします。
Openpyxl は、Excel ファイルからの読み取りまたは Excel ファイルへの書き込みに使用される Python ライブラリです。
filenameという変数を作成し、そこに試験結果.xlsxのアドレスを代入します。
filename = "/content/試験結果.xlsx"
wbという変数を作成し、Openpyxlのload_workbookメソッドを使い、ブックを開きます。
wb = op.load_workbook(filename, data_only=True)
またwsという変数には、wb['結果']というシートを代入します。
ws = wb['結果']

12. For文を使ってシート内のデータを読み込みます。
VBAで書くマクロコードとの違いは、閉じるためのコードがないことです。
インデントが、文法の一部になっています。

For文のコード
13.for row in ws.iter_rows() の部分を解説します。
for row inに続く、”ws.iter_rows(min_row=1, max_col=6, max_row=ws.max_row):”
の説明です。
ws.iter_rowsの部分
iter_rows() は、openpyxl ライブラリを使用して、Excelシートの行を反復処理するためのメソッドです。

14. iter_rows() メソッドには、
行を反復する範囲を指定するための5つの引数があります。
min_row: 反復処理を開始する行の番号を指定します。この引数を設定しない場合、最初の行(通常は1行目)から開始されます。
max_row: 反復処理を終了する行の番号を指定します。この引数を設定しない場合、最後の行まで反復処理されます。
min_col: 反復処理を開始する列の番号を指定します。この引数を設定しない場合、最初の列(通常はA列)から開始されます。
max_col: 反復処理を終了する列の番号を指定します。この引数を設定しない場合、最後の列まで反復処理されます。
values_only: True に設定すると、セルオブジェクトではなく、そのセルの値のみが返されます。
| パラメーター: | 意味 |
|---|---|
| min_col (int) | 最小の列インデックス (1 から始まるインデックス) |
| min_row (int) | 最小の行インデックス (1 から始まるインデックス) |
| max_col (int) | 最大の列インデックス (1 から始まるインデックス) |
| max_row (int) | 最大の行インデックス (1 から始まるインデックス) |
| value_only (bool) | セル値のみを返すかどうか |
15.今回の動画のコードは、ワークシートの1行目から最後の行まで、
最初の列から6列目までのデータを反復処理します。
max_row=ws.max_row はシートで使用されている最終行 のことです。
VBAとの違いは、最終行のコードを書かなくても、ws.max_rowで取得できる点です。
row_data = [] は,
取得した行のデータを格納するための空のリストです。
for cell in row:、さらにFor文が入れ子になっていますが、このコードで、対象の行のセルについて、If文で条件を出しています。
if cell.column == 6 and cell.data_type == 'f':
6列目であり、それが数式ならば、row_data.append(cell.value) とし、値を入れろとしています。

実行すると、print()関数で、以下のように取得したデータを画面にプリントします。
import openpyxl as op
# 既存Excelブックの読み込み
filename = "試験結果.xlsx"
wb = op.load_workbook("試験結果.xlsx")
# シート名
ws = wb['結果']
# シート内のデータを読み出す
for row in ws.iter_rows(min_row=1, max_col=6, max_row=ws.max_row, values_only=True):
print(row)
次回予告「読み込んだデータから条件に合ったデータを探す」
16. さらにコードを追加してみます。
6列目の値が<160 ならばそのデータを補習者.xlsx に書き込むというものです。
そして、その補習者.xlsxを別名のブックとして保存します。
これによりひな形にデータは保存されず、再度利用可能です。

17.実行すると、160点以下の生徒名が抽出され別名でセッションストレージに作成されました。

18.ブックをダウンロードして確認してみましょう。作成されたブック名を右クリックして、ダウンロードを選択します。
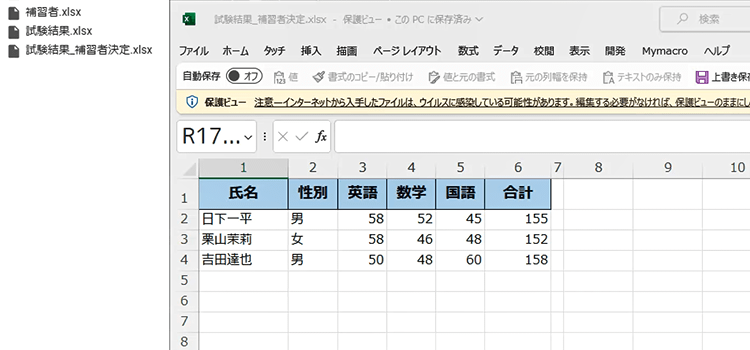
19. ブックを開くと、補習が必要な生徒名が抽出されたことがわかります。
取得したデータから条件に合致するデータを別ブックに書き出す、2つめのコードの全体
Colaboratory で使用したコード
import openpyxl as op
# 既存Excelブックの読み込み
filename = "試験結果.xlsx"
wb = op.load_workbook("試験結果.xlsx")
# シート名
ws = wb['結果']
# シート内のデータを読み出す
for row in ws.iter_rows(min_row=1, max_col=6, max_row=ws.max_row, values_only=True):
print(row)
import openpyxl as op
import os
# 元のファイルを読み込み
source_file = "/content/試験結果.xlsx"
wb = op.load_workbook(source_file, data_only=True)
ws = wb.active
# 補習者.xlsx ファイルをひな形として読み込む
template_file = "/content/補習者.xlsx"
new_wb = op.load_workbook(template_file)
new_ws = new_wb.active
# 補習者.xlsxの既存データの最終行を見つける
last_row = new_ws.max_row
# 合計点数が160未満の生徒を探す
for row in ws.iter_rows(min_row=2, max_col=6, max_row=ws.max_row, values_only=True):
# 合計点数を確認
if row[5] is not None and row[5] < 160:
# 補習者リストに追加
last_row += 1 # 新しい行にデータを追加するため、行番号を増やす
for col, value in enumerate(row, start=1):
new_ws.cell(row=last_row, column=col, value=value)
# 保存ファイル名の作成
xlsx_file = "/content/試験結果.xlsx"
file_name = os.path.splitext(os.path.basename(xlsx_file))[0]
new_wb.save(f"/content/{file_name}_補習者決定.xlsx")