いきなり始めるPython × Excel5回、複数ブックからデータを取り込んで1つのブックにまとめて転記する。
いきなり始めるPython × Excel5回、複数ブックからデータを取り込んで1つのブックにまとめて転記する。

VBAユーザーの為のPYTHON 05回
複数のExcelブックからデータを1つにまとめる
この記事で学べる内容
- Excel VBAでやっていた「複数ブックのデータを1つにまとめる」処理を、Google Colab上のPythonでも同じように実現できることを理解する
- ColabでGoogleドライブをマウントし、/content/drive/My Drive/ 配下のExcelファイルにアクセスする手順を確認する
- pandasとosモジュールをインポートして、フォルダ内のExcelファイルを一括で処理する基本形(import pandas as pd / import os)を学ぶ
- まとめ用のブック(matome.xlsx)を先に読み込み、そこへ支店別・ファイル別のデータを順番に追加していくという「土台を先に読む」考え方を理解する
- os.listdir() でフォルダ内のファイル一覧を取得し、if filename.endswith('.xlsx') でExcelだけを対象にする実務的な判定方法を学ぶ
- pd.read_excel(...) で各支店ブックをDataFrameとして読み込み、pd.concat([...], ignore_index=True) で1つの表に結合する処理の流れを身につける
- 結合した結果を to_excel(...) でGoogleドライブ内に書き出し、あとから開いて確認できるようにする保存処理を学ぶ
- for文とインデントだけでVBAのFor~NextやEnd Ifに相当する処理を書ける、Pythonらしいコードスタイルを確認する
- pandasが持つ読み込み・書き出し・結合・クリーニングといった機能を使えば、Excelで作業していた「毎月の集計」や「支店データの統合」を自動化できることをイメージできる
マクロ講座中級編の51回で解説した複数ブックのデータを1つにまとめるというEXCELVBAのマクロと同じことを、Google Colaboratry上のPythonで行います。
同じ事をするのですが、Pythonではとてもコードがシンプルで、そんなに簡単でいいのか?と思うかもしれません。
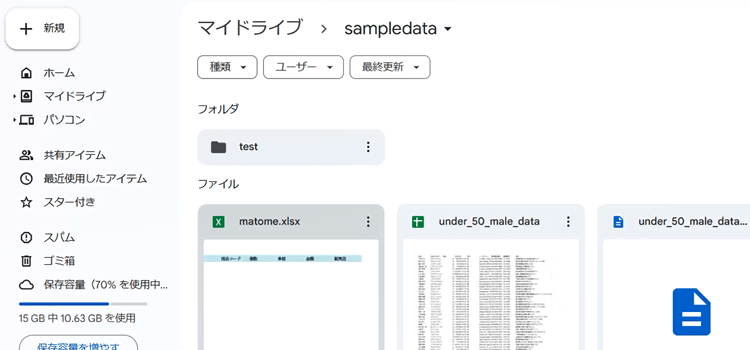
前提条件GoogleDriveのマイドライブにsampledate というフォルダを作成し、その中に必要なまとめブックがあり、さらにtestというフォルダに支店別のブックが今回は合計5つ入っています。
Pythonで複数のExcelブックからデータを1つにまとめる
【動画で学べる内容】使いやすくするために関数を作る
●1.Googleドライブをマウントする方法。 Google DriveをColaboratoryにマウントして、ファイルにアクセスできるようにします。
●2. pandasをインポートします。`pandas` ライブラリを使用してExcelファイルを読み込みます。
●3.データの結合。複数のブックのデータを1つのデータフレームに結合します。
●4.結果の保存。結合したデータを新しいExcelファイルに保存します。
複数のExcelブックからデータを1つにまとめる
1. 今回も、使用するブックをGoogleドライブにアップロードしておきます。そしてColab側では、マウントボタンをクリックするか、マウントのコードを記述し実行します。
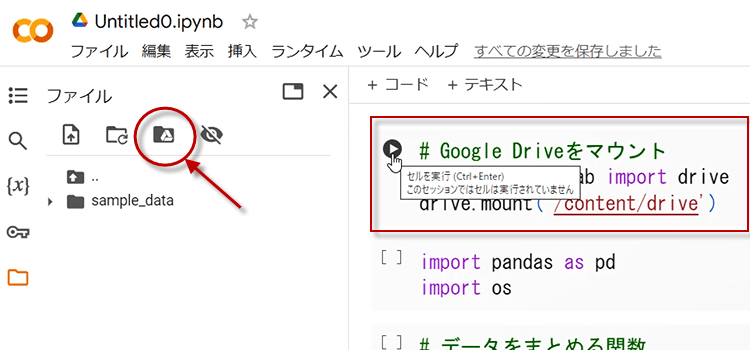
2. 次にpandasと osをインポートします。
pandasとは、pythonにおいてデータ操作したり、データ解析を行うことのできるライブラリで、csvファイルを読み取る機能や、Excelのデータを取り込む機能、データをグラフ化する機能を備えています。
OSモジュールとは、Pythonコードを、さまざまOSで使えるようにするためのモジュールで、 OSモジュールを使えば、ファイルやディレクトリの操作が簡単にできるようになります。
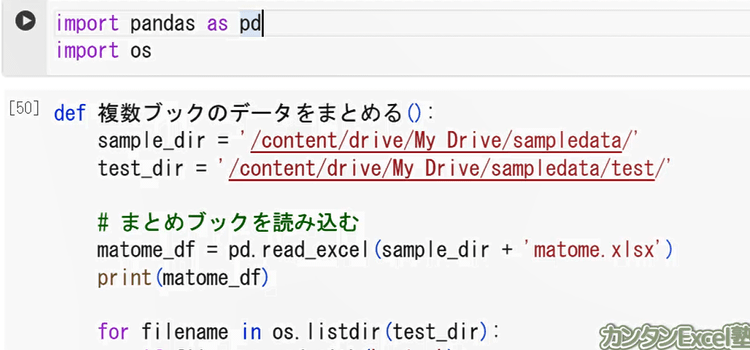
import pandas as pd
import os
3. Googleドライブには事前にsampledataというフォルダにファイルをアップロードしてあります。
4.次に、データをまとめる関数を作成します。
「def 複数ブックのデータをまとめる():」と記述して:をつけます。
コロン:以下のインデントされた部分が関数の中身です。
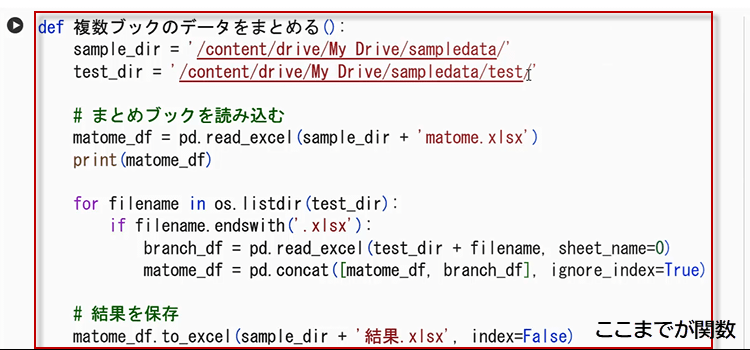
自作関数コードの説明pandasのread_excel関数
5. 最初にマウントしたフォルダと、その中のフォルダアドレスを扱いやすいように変数に入れます。
sample_dir = '/content/drive/My Drive/sampledata/' test_dir = '/content/drive/My Drive/sampledata/test/'
次に、まとめるために用意したブックを読み込みます。matome_dfという変数を指定します。
pandasのread_excel関数を利用して、指定したフォルダにある'matome.xlsx'を読込、 matome_df に入れます。
matome_df = pd.read_excel(sample_dir + 'matome.xlsx')
”# まとめブックを読み込む”の部分はコメントです。
実際の操作コードは次のFor文の繰り返し処理からです。
6. PythonのFor文を使います。
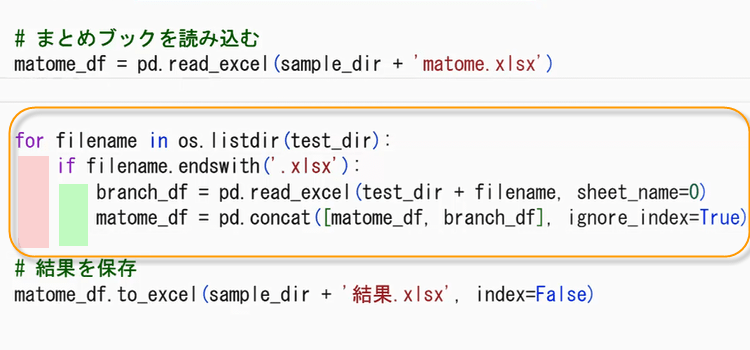
for filename in os.listdir(test_dir):
そのFor文中にIfを入れ子 で使用しています。
VBAと違い、最後のNext文はありません。インデントが文法の役目を持っていますので、For文の影響下にあるブロックをインデントが表します。また、If文の終了を知らせるEndIfも必要ありません。
for filename in os.listdir(test_dir):
if filename.endswith('.xlsx'):
branch_df = pd.read_excel(test_dir + filename, sheet_name=0)
matome_df = pd.concat([matome_df, branch_df], ignore_index=True)
この行は、`test_dir` というフォルダ内のすべてのファイル名を一つずつ取り出すためのループを作成しています。
`os.listdir(test_dir) ` は、`test_dir` フォルダ内のすべてのファイルとフォルダの名前のリストを返します。
このループは、そのリスト内の各要素(つまり、各ファイル名)に対して一つずつ操作を行います。
os.listdir()メソッドとは
7.osモジュールの os.listdir でファイル・ディレクトリの一覧を取得します。
for filename in
os.listdir(test_dir):のos.listdir(test_dir)の部分でtest_dir 変数で指定したアドレスのフォルダ内のファイル一覧を取得します。

8. `if filename.endswith(".xlsx"):`
この行は、ファイル名が ".xlsx" で終わるかどうかをチェックしています。
もしそうなら、そのファイルに対して以下の操作を行います。
if filename.endswith('.xlsx'):
Excelファイルであれば、次の処理をします。
branch_df = pd.read_excel(test_dir + filename, sheet_name=0)
`pd.read_excel()` 関数 を使って、Excelファイルを読み込んでいます。
`test_dir + filename` はファイルの完全なパスを意味し、`sheet_name=0` はExcelファイルの最初のシート(インデックス0が最初のシートを意味します)を読み込むことを示しています。
読み込んだデータは `branch_df ` という変数にDataFrameとして保存されます。
matome_df = pd.concat([matome_df, branch_df], ignore_index=True)
`pd.concat()` 関数を使って、元の `matome_df` DataFrame(まとめるデータ)と新しく読み込んだ `branch_df` DataFrameを結合しています。
`ignore_index=True` は、結合後のDataFrameで新しいインデックスを作成することを意味します。
複数のExcelブックからデータを読み込み、それらを一つのDataFrameに結合しているのがこのFor文からのコードの役割になります。
9.最後に`def 複数ブックのデータをまとめる():` で始まる関数は、For文内の処理をto_exceメソッドでまとめて終了します。
下記コードは結合したデータを新しいExcelファイルとして保存する命令です。
また関数だけでは動きませんから、実行するコードを追加します。
# 結果を保存
matome_df.to_excel(sampledate_dir + "結果.xlsx", index=False)
# 関数を実行 複数ブックのデータをまとめる() # 結果ファイルのパス result_file_path = '/content/drive/My Drive/sampledata/結果.xlsx' # Excelファイルを読み込む result_df = pd.read_excel(result_file_path) # データを表示 print(result_df)

データをまとめた結果を確認する
関数を実行後、保存したブックを開いて確認した画像です。
9. 以下のコードは今回Google Colaboratry上のPythonで実行したコードになります。
# Google Driveをマウント
from google.colab import drive
drive.mount('/content/drive')
import pandas as pd
import os
def 複数ブックのデータをまとめる():
sample_dir = '/content/drive/My Drive/sampledata/'
test_dir = '/content/drive/My Drive/sampledata/test/'
# まとめブックを読み込む
matome_df = pd.read_excel(sample_dir + 'matome.xlsx')
for filename in os.listdir(test_dir):
if filename.endswith('.xlsx'):
branch_df = pd.read_excel(test_dir + filename, sheet_name=0)
matome_df = pd.concat([matome_df, branch_df], ignore_index=True)
# 結果を保存
matome_df.to_excel(sample_dir + '結果.xlsx', index=False)
# 関数を実行
複数ブックのデータをまとめる()
Pythonの`pandas`ライブラリの機能にはどんな物があるか
`pandas`はデータ分析と操作のためのライブラリです。主に以下のような機能があります:
1. DataFrameとSeries:
Pandasの中心的な概念です。DataFrameは表形式のデータを表し、SeriesはDataFrameの各列を表します。
2. データの読み込みと書き出し:
read_csv(), read_excel(), to_csv(), to_excel() などのメソッドを使用して、様々なフォーマットのデータを読み込み、書き出すことができます。
3. データの操作:
head(), tail(), describe(), groupby(), merge(), concat(), join() などのメソッドを使って、データの選択、フィルタリング、集約、結合などを行うことができます。
4. データのクリーニング:
dropna(), fillna(), drop_duplicates() などのメソッドを使って、欠損値の処理や重複の削除など、データのクリーニングを行うことができます。
5. データの可視化:
PandasはMatplotlibと統合されており、`plot()` メソッドを使ってデータの可視化を簡単に行うことができます。